1131. Data Structure - HashMapHash, Load Factor, and Rehashing
Implement HashMap with array and linked list.
1. Concepts in HashMap(or Hash Table)
1.1 Hash Code and Compressor
Hash code is an Integer number (random or nonrandom). In Java every Object has its own hash code. We will use the hash code generated by JVM in our hash function and to compress the hash code we modulo(%) the hash code by size of the hash table. So modulo operator is compressor in our implementation.
1.2 Hash Function
Hash function hashes (converts) a number in a large range into a number in a smaller range. This smaller range corresponds to the index numbers in an array.
private int hashFunc(K key) {
int hashCode = key.hashCode();
int index = hashCode % numBuckets;
return index;
}
1.3 Collision
If multiple keys has same hashCode, then collision occurs. Approaches to solve collision:
- Open Addressing: move to an empty cell.
clusteringissue may happen. - Separate Chaining: store values in linked list instead of themselves.
1.4 Open Addressing Vs Separate Chaining
If open addressing is to be used, double hashing seems to be the preferred system by a small margin over quadratic probing. The exception is the situation in which plenty of memory is available and the data won’t expand after the table is created; in this case linear probing is somewhat simpler to implement and, if load factors below 0.5 are used, causes little performance penalty.
If the number of items that will be inserted in a hash table is unknown when the table is created, separate chaining is preferable to open addressing. Increasing the load factor causes major performance penalties in open addressing, but performance degrades only linearly in separate chaining.
When in doubt, use separate chaining. Its drawback is the need for a linked list class, but the payoff is that adding more data than you anticipated won’t cause performance to slow to a crawl.
1.5 Load Factor and Rehashing
Load Factor is the ratio of the number of items in a hash table to its size. If the total number of buckets is 10 and 7 of them got filled now, the load factor is 7/10=0.7.
In our implementation whenever we add a key value pair to the Hash Table we check the load factor if it is greater than 0.7 we double the size of our hash table.
2. Implementing HashMap
2.1 Structure of HashMap
An array list contains Hash Nodes. Each node can have none or multiple descendant nodes. They have the same index, but contains different hashcode.
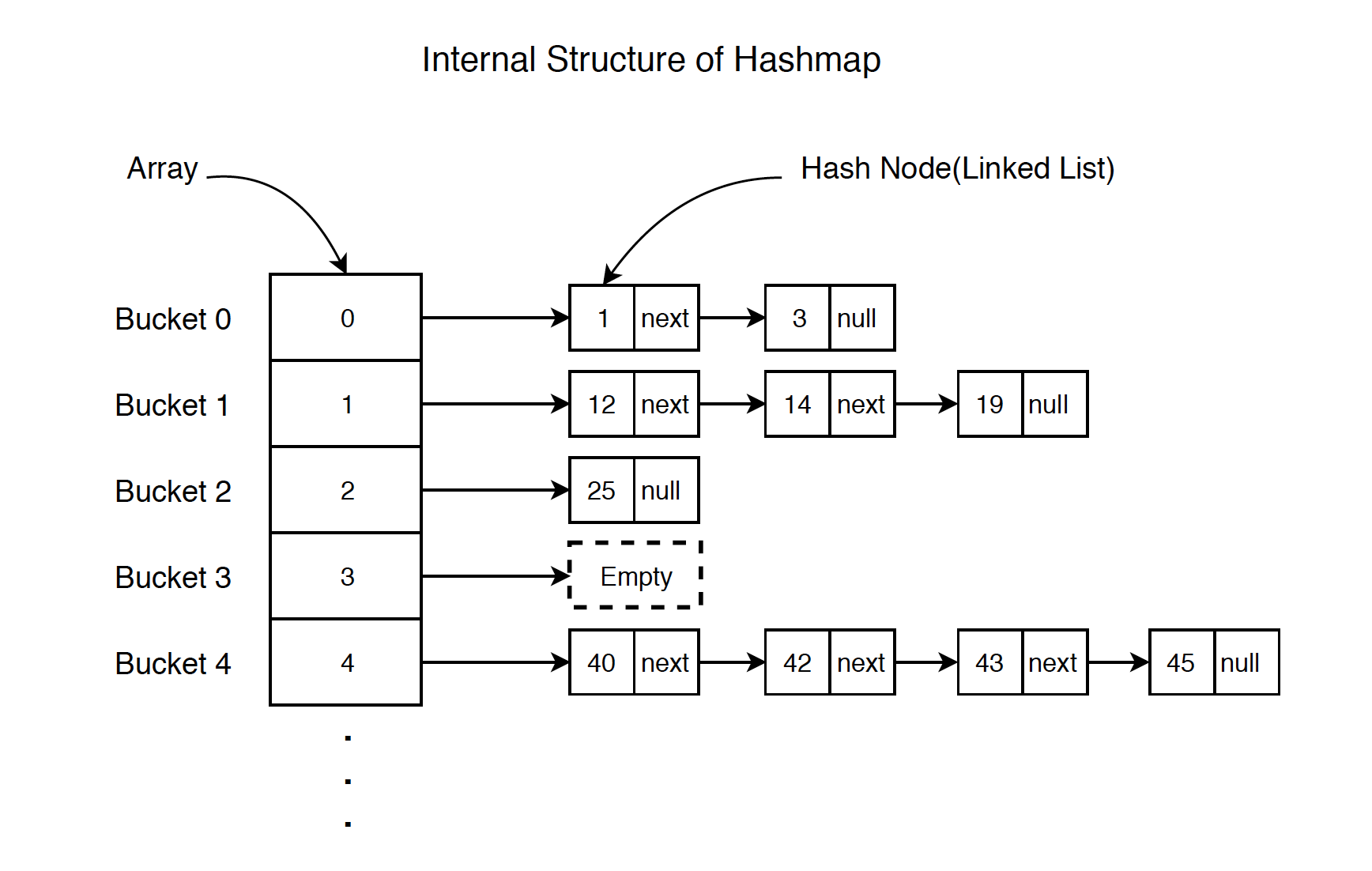
2.2 Common Operations for HashMap
- get(key): returns the value corresponding to the key if the key is present in HashMap
- add(key, value): adds new valid key, value pair to the HashMap, if already present updates the value
- remove(key): removes the key, value pair
- size(): return the size of the HashMap
- isEmpty(): returns true if size is zero
2.3 Time Complexity
- get: $O(1)$
- add: $O(1)$
- remove: $O(1)$
2.4 HashNode
HashNode is a storage unit for storing date. It has the next attribute pointing to the next hashnode, behaves like a linked list.
public class HashNode<K, V> {
public K key;
public V val;
public HashNode<K, V> next;
public HashNode(K key, V val) {
this.key = key;
this.val = val;
this.next = null;
}
}
2.5 Implementation of HashMap
Generic HashMap.
public class HashMap<K, V> {
// bucketArray is used to store array of chains
private ArrayList<HashNode<K, V>> bucketList;
// Current capacity of array list
private int numBuckets;
// Current size of array list
private int size;
// Constructor (Initializes capacity, size and empty chains.
public HashMap() {
bucketList = new ArrayList<>();
numBuckets = 10;
size = 0;
// Create empty chains
for (int i = 0; i < numBuckets; i++) {
bucketList.add(null);
}
}
public int size() {
return size;
}
public boolean isEmpty() {
return size() == 0;
}
// Returns value for a key
public V get(K key) {
// Find head of chain for given key
int bucketIndex = hashFunc(key);
HashNode<K, V> head = bucketList.get(bucketIndex);
// Search key in chain
while (head != null) {
if (head.key.equals(key)) {
return head.val;
}
head = head.next;
}
// If key not found
return null;
}
// Adds a key value pair to hash
public void add(K key, V value) {
// Find head of chain for given key
int bucketIndex = hashFunc(key);
HashNode<K, V> head = bucketList.get(bucketIndex);
// Check if key is already present
while (head != null) {
if (head.key.equals(key)) {
head.val = value;
return;
}
head = head.next;
}
// Insert key in chain
size++;
head = bucketList.get(bucketIndex);
HashNode<K, V> newNode = new HashNode<K, V>(key, value);
newNode.next = head; // add to header
bucketList.set(bucketIndex, newNode);
// If load factor goes beyond threshold, then double hash table size
if ((1.0*size)/numBuckets >= 0.7) {
ArrayList<HashNode<K, V>> tempList = bucketList;
bucketList = new ArrayList<>();
numBuckets = 2 * numBuckets; // double the capacity
size = 0;
for (int i = 0; i < numBuckets; i++) {
bucketList.add(null);
}
for (HashNode<K, V> headNode : tempList) { // traverse array
while (headNode != null) { // traverse each linked list
add(headNode.key, headNode.val);
headNode = headNode.next;
}
}
}
}
// Method to remove a given key
public V remove(K key) {
// Apply hash function to find index for given key
int bucketIndex = hashFunc(key);
// Get head of chain
HashNode<K, V> head = bucketList.get(bucketIndex);
// Search for key in its chain
HashNode<K, V> prev = null;
while (head != null) {
// If Key found
if (head.key.equals(key)) {
break;
}
// Else keep moving in chain
prev = head;
head = head.next;
}
// If key was not there
if (head == null) {
return null;
}
// Reduce size
size--;
// Remove key
if (prev != null) {
prev.next = head.next;
} else {
bucketList.set(bucketIndex, head.next);
}
return head.val;
}
// hash function
private int hashFunc(K key) {
int hashCode = key.hashCode();
int index = hashCode % numBuckets;
return index;
}
}
Integer type, implemented with node.
class MyHashMap {
class HashNode {
int key, val;
HashNode next;
HashNode(int key, int val) {
this.key = key;
this.val = val;
}
}
HashNode[] bucket;
/** Initialize your data structure here. */
public MyHashMap() {
bucket = new HashNode[1000000];
}
/** value will always be non-negative. */
public void put(int key, int value) {
int hash = hashFunc(key);
if (bucket[hash] == null) {
bucket[hash] = new HashNode(key, value);
} else {
HashNode header = bucket[hash];
while (header != null && header.next != null) {
if (header.key == key) {
header.val = value;
return;
}
header = header.next;
}
if (header.key == key) {
header.val = value;
} else {
header.next = new HashNode(key, value);
}
}
}
/** Returns the value to which the specified key is mapped, or -1 if this map contains no mapping for the key */
public int get(int key) {
int hash = hashFunc(key);
if (bucket[hash] == null) {
return -1;
} else {
HashNode header = bucket[hash];
while (header != null) {
if (header.key == key) {
return header.val;
}
header = header.next;
}
return -1;
}
}
/** Removes the mapping of the specified value key if this map contains a mapping for the key */
public void remove(int key) {
int hash = hashFunc(key);
if (bucket[hash] == null) {
return;
} else {
HashNode dummy = new HashNode(0, 0);
dummy.next = bucket[hash];
HashNode prev = dummy;
HashNode curr = dummy.next;
while (curr != null) {
if (curr.key == key) {
prev.next = curr.next;
break;
}
curr = curr.next;
prev = prev.next;
}
bucket[hash] = dummy.next;
}
}
private int hashFunc(int key) {
return key % 1000000;
}
}
2.6 Implementation of HashSet
Implemented with node.
public class MyHashSet {
class HashNode {
int key;
HashNode next;
HashNode(int key) {
this.key = key;
}
}
HashNode[] bucket;
public MyHashSet() {
bucket = new HashNode[1000000];
}
public void add(int key) {
int hash = hashFunc(key);
if (bucket[hash] == null) {
bucket[hash] = new HashNode(key);
} else {
HashNode header = bucket[hash];
while (header != null) {
if (header.key == key) {
return;
}
if (header.next == null) {
header.next = new HashNode(key);
} else {
header = header.next;
}
}
}
}
public void remove(int key) {
int hash = hashFunc(key);
if (bucket[hash] == null) {
return;
} else {
HashNode dummy = new HashNode(0);
dummy.next = bucket[hash];
HashNode prev = dummy;
HashNode curr = dummy.next;
while (curr != null) {
if (curr.key == key) {
prev.next = curr.next;
break;
}
curr = curr.next;
prev = prev.next;
}
bucket[hash] = dummy.next;
}
}
public boolean contains(int key) {
int hash = hashFunc(key);
if (bucket[hash] == null) {
return false;
} else {
HashNode header = bucket[hash];
while (header != null) {
if (header.key == key) {
return true;
}
header = header.next;
}
return false;
}
}
private int hashFunc(int key) {
return key % 1000000;
}
}
Implemented with array.
public class MyHashSet {
int[] arr;
private int capacity = 1000000;
// Initialize your data structure here.
public MyHashSet() {
arr = new int[capacity];
// Create empty chains
for (int i = 0; i < capacity; i++) {
arr[i] = Integer.MIN_VALUE;
}
}
public void add(int key) {
int hash = hashFunc(key);
arr[hash] = key;
}
public void remove(int key) {
int hash = hashFunc(key);
if (arr[hash] == key) {
arr[hash] = Integer.MIN_VALUE;
}
}
public boolean contains(int key) {
int hash = hashFunc(key);
return arr[hash] != Integer.MIN_VALUE;
}
// hash function
private int hashFunc(int key) {
return key % capacity;
}
}